Des outils pour entreprendre l’analyse de données
par Nicolas Sacchetti
« Transformer les nouvelles découvertes scientifiques en applications concrètes pour le bénéfice de l’ensemble de la société » est ce à quoi IVADO, un institut québécois du domaine de l’intelligence numérique (IN), se dédie. Jean-François Connolly est conseiller IVADO en IN. Il présente quelques outils pour entreprendre des projets d’analyse de données en sciences humaines.

L’événement a eu lieu en visioconférence lors du Congrès P4IE sur les politiques, les pratiques et les processus liés à la performance des écosystèmes d’innovation. Présenté par le Partenariat pour l’organisation de l’innovation et des nouvelles technologies 4POINT0, du 11 au 13 mai 2021.
L’IN n’est pas l’intelligence artificielle (IA). IVADO définit l’IN comme étant un : « Ensemble d’outils et de méthodologies combinant collecte et exploitation des données avec conception et utilisation de modèles et d’algorithmes pour faciliter, enrichir et accompagner la prise de décisions. »
Comprendre : l’intelligence des affaires
Le but est de comprendre les données de la firme. Comprendre le monde et le contextualiser avec les données qui s’y rattachent. Pour les chercheurs, un tableau de bord permet de voir les variations et de suivre une situation en temps réel.

Les données peuvent se retrouver en grappe (cluster) d’informations de différentes couleurs, ce qui en fait un groupe. La réduction de la dimensionnalité (dans l’univers virtuel, le nombre de dimensions se compte par centaines +++) consiste à identifier les informations redondantes et de les enlever. Le conseiller en IN Jean-François Connolly propose un logiciel PCA (Principal Component Analysis) pour analyser les grappes de données qui se gère à partir d’Excel de la suite Microsoft.

De plus, il mentionne l’algorithme t-SNE (t-distributed stochastic neighbor embedding). « Il s’agit d’une méthode non linéaire permettant de représenter un ensemble de points d’un espace à grande dimension dans un espace de deux ou trois dimensions. Les données peuvent ensuite être visualisées avec un nuage de points. » Le logiciel est disponible sur scikit-learn.org en code ouvert (open source).
Les 8 règles de Nelson1
Jean-François Connolly invite à se rappeler quelques règles simples pour l’analyse sans passer par l’IA. C’est alors qu’il mentionne Lloyd S. Nelson qui mit à jour en 1984 les Règles électriques occidentales (règles WECO). L’intention est de rendre la probabilité de détecter une condition hors de contrôle. « Ces règles font très bien le travail pour suivre des opérations industrielles », dit Connolly. (1https://en.wikipedia.org/wiki/Nelson_rules )
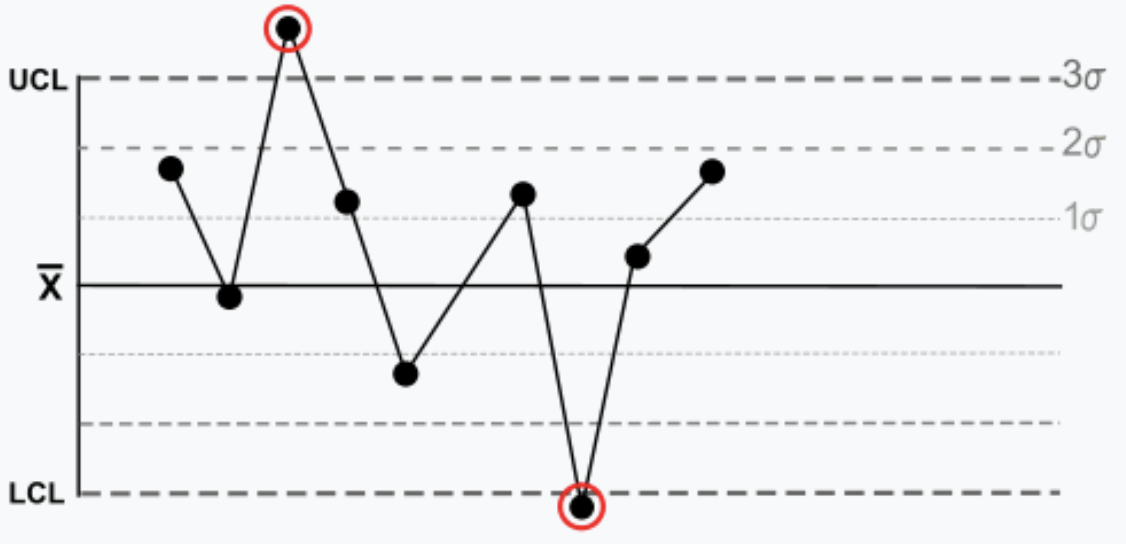
Règle 1 : Un point correspond à plus de 3 écarts types par rapport à la moyenne. Il est hors de contrôle.
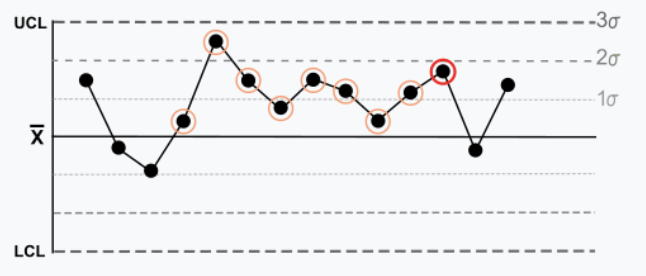
Règle 2 : Neuf ou + points d’affilée sont du même côté de la moyenne. Certains biais prolongés existent.
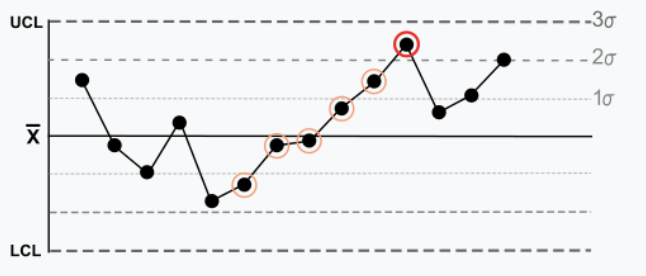
Règle 3: Six ou + points d’affilée augmentent (ou diminuent) continuellement, décrivent une tendance.
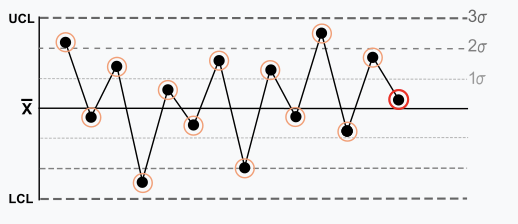
Règle 4 : Quatorze points ou + dans une rangée alternent dans la direction. Une telle oscillation est au-delà du bruit. La règle ne concerne que la directionnalité. La position de la moyenne et la taille de l’écart-type n’ont aucune incidence.
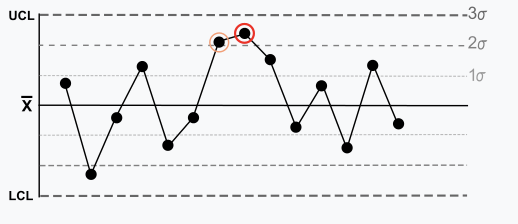
Règle 5 : Deux/trois points sur trois dans une rangée sont à plus de 2 écarts types de la moyenne dans la même direction. Il y a une tendance moyenne pour les échantillons à être hors de contrôle. Le côté de la moyenne pour le troisième point est indéterminé.
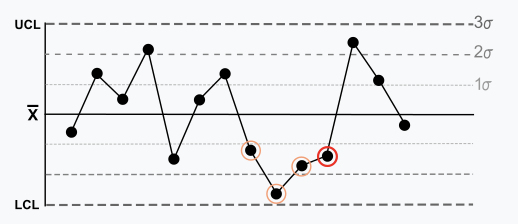
Règle 6 : Quatre/cinq points sur cinq dans une rangée ont plus d’un écart type de la moyenne dans la même direction. Il y a une forte tendance à ce que les échantillons soient légèrement hors de contrôle. Le côté de la moyenne pour le cinquième point est indéterminé.
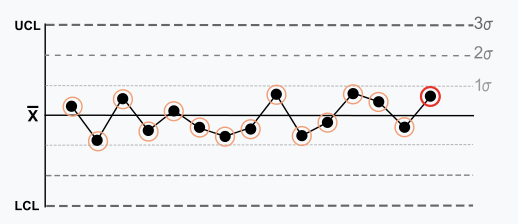
Règle 7: Quinze points dans une rangée sont tous situés à moins d’un écart-type de la moyenne, de part et d’autre de celle-ci. Avec un écart-type de 1, on s’attend à une plus grande variation.
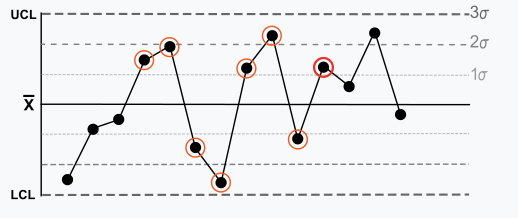
Règle 8 : Il existe huit points dans une rangée, mais aucun ne se situe à moins d’un écart-type de la moyenne, et les points sont dans les deux directions de la moyenne. Sauter du haut vers le bas en manquant la première bande d’écart type est rarement aléatoire.
Prédire : l’apprentissage automatique (machine learning)
Le but est de faire des prédictions résultant à des probabilités. « Alors que les gens parle de l’IA, en fait, il s’agit d’apprentissage automatique », explique M. Connolly. Tous les types de données ne sont pas égaux. Les données étiquetées ont une valeur ajoutée, mais aussi plus onéreuses. L’étiquetage est utile afin d’identifier ce qu’ils représentent, et que l’IN puisse les classer ou de « faire une réduction des données en vue de représenter un phénomène par une loi simplificatrice », soit une régression mathématique.

L’apprentissage automatique est basé sur un modèle mathématique de régression linéaire. C’est un modèle qui cherche à établir une relation rectiligne entre des variables dites expliquées y , et celles explicatives x. On peut par la suite faire des prédictions sur des variables mêmes inconnues à partir de celles connues.
Voilà ce que l’analytique de l’apprentissage automatique fait. « Analytique : Technique de recherche consistant à analyser les mégadonnées à l’aide d’algorithmes, d’outils spécialisés ou de systèmes d’IA dans le but d’obtenir des informations utiles à l’action ou à la prise de décision » Donc prédire.
Le conseiller d’IVADO en intelligence numérique propose le documentaire AlphaGo réalisé par Greg Kohs, lorsqu’il aborde la consolidation des apprentissages. « Le Go est le jeu le plus complexe jamais conçu par l’homme. Battre un joueur professionnel de Go est un incroyable défi de longue date pour la recherche sur l’IA. » — tiré du documentaire AlphaGo
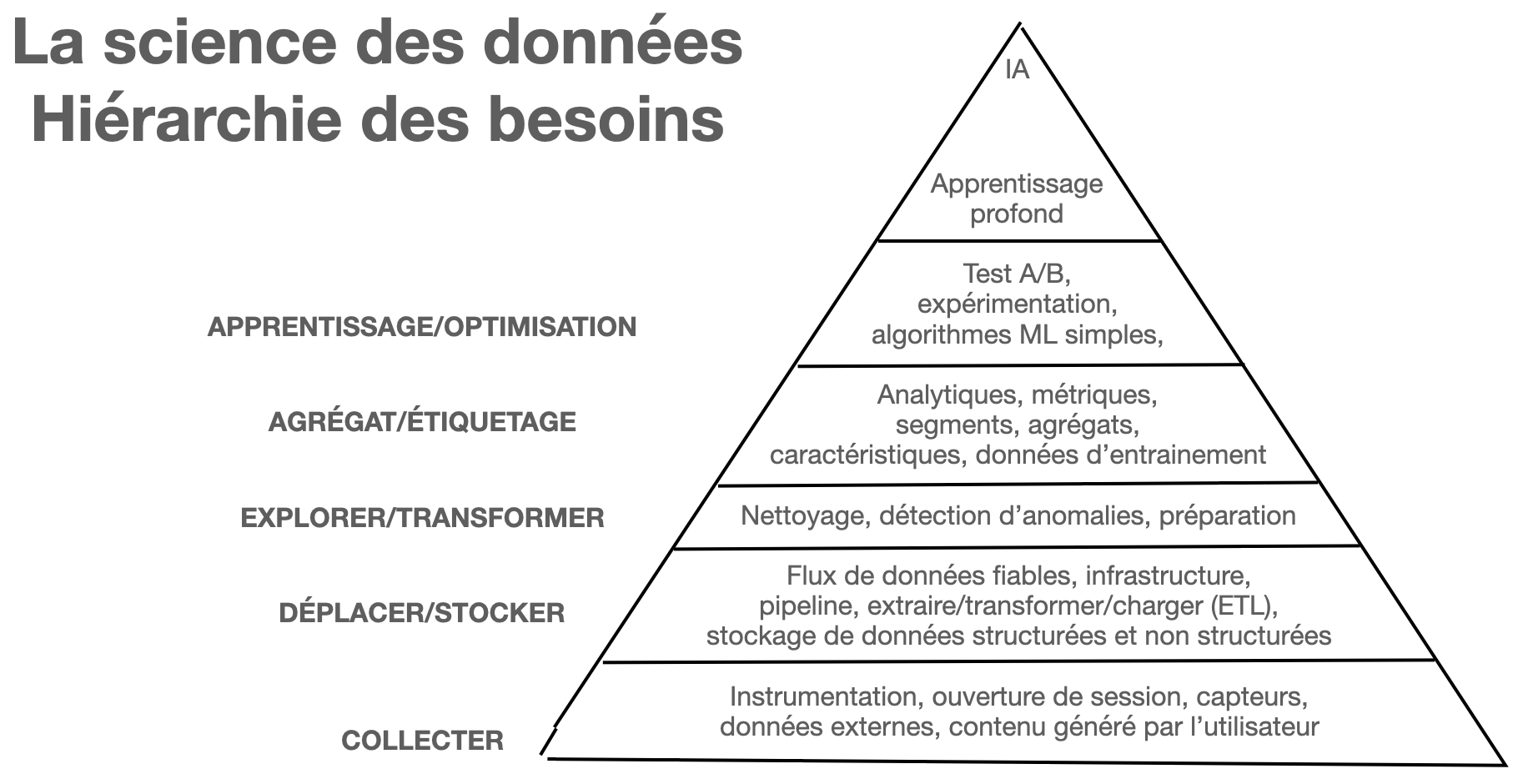
L’apprentissage de l’IA est comme une pyramide de Maslow ayant à son sommet l’IA. Il faut fondamentalement savoir collecter les données, avant d’apprendre à les déplacer et les conserver, pour être en mesure de les explorer et de les transformer. Viens après, l’agrégation et l’étiquetage, qui impliquent le tableau de bord, avant de se rendre à l’optimisation et l’apprentissage profond de l’IA.
Pour identifier les opportunités à l’aide de l’apprentissage automatique, il explique de prendre un processus et de le morceler en prédictions. Il donne l’exemple d’un Chatbot, un programme qui tente de converser avec un utilisateur. Son processus se morcèle en tâches. I- Avoir une conversation. II- Comprendre le contexte. III- Décrire la situation. IV- Recommander la ressource appropriée.
Pour chacune des tâches, les formuler en prédiction. L’utilisation d’un Canevas IA ( Ajay Agrawal et al.) est utile pour réfléchir à la manière dont l’IA pourrait aider à la prise de décision dans l’entreprise. Il cartographie ce qui entoure une prédiction. Voici les éléments de réflexions. (Harvard Business Review)
| Prédiction | Jugement | Action | Résultats |
| Que devez-vous savoir pour faire votre prédiction ? | Comment évaluer-vous les différents résultats et erreurs ? | Qu’essayez-vous d’accomplir ? | Quelle est votre échelle de réussite des tâches accomplies ? |
| Saisi | Consolidation des apprentissages | Rétroaction |
| De quelles données avez-vous besoin pour exécuter l’algorithme prédictif ? | De quelles données avez-vous besoin pour entraîner l’algorithme prédictif ? | Comment pouvez-vous utiliser les résultats pour améliorer l’algorithme ? |
Lectures
Jean-François Connolly recommande ces lectures sur l’intelligence numérique.
- O’Neil, Catherine. 2016. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy . Crown Book.
- Agrawal, Ajay et al. 2018. Prediction Machines: The Simple Economics of Artificial Intelligence. Harvard Business Review Press.
- Galloway, Scott. 2017. the four: The Hidden DNA of Amazon, Facebook and Google. Portfolio.
- Joansson, frans. 2017. The Medici Effect: What Elephants and Epidemics Can Teach Us About Innovation. Portfolio.
Ce contenu a été mis à jour le 2022-09-27 à 23 h 38 min.