Introduction au traitement du langage naturel avec Python
par Nicolas Sacchetti
Le 27 octobre 2022, Davide Pulizzotto et Bruno Agard de l’École Polytechnique Montréal animaient la première partie de l’atelier, axée sur les nouvelles méthodes d’analyse et leur impact sur la gestion des mégadonnées. Je vous propose ici quelques notions pour approfondir votre compréhention sur le TALN – NLP (natural language processing).
Davide Pulizzotto, docteur en sémiotique, est spécialisé en analyse de texte assistée par ordinateur dans le domaine des sciences sociales, une approche aussi connue sous le nom de text mining for humanities. De son côté, Bruno Agard se distingue par sa spécialisation dans la valorisation des données. Il est également professeur titulaire au département de mathématiques et génie industriel et y dirige le laboratoire d’IA.
Cet article sert de ressource complémentaire pour enrichir votre compréhension avant de visionner l’atelier. Il n’est pas un substitut à l’atelier lui-même. Après avoir lu cet article, je vous encourage à regarder l’atelier concerné sur la chaîne YouTube de 4POINT0.
L’atelier est une initiation à l’analyse de données textuelles et à l’utilisation des méthodes d’analyse des données qui viennent du paradigme de l’apprentissage automatique (machine learning).
La première partie aborde le prétraitement des données textuelles ainsi que l’analyse des sentiments, aussi connue sous le nom de sentiment analysis. Quant à la seconde partie, elle se concentrera sur la construction de modèles d’apprentissage, à la fois supervisés et non supervisés.
Les deux spécialistes expliquent leur choix de données textuelles afin de présenter une perspective typique d’analyse dans le domaine des sciences sociales et humaines (ssh).
L’atelier se déroule sur Google Colaboratory. Un environnement essentiellement infonuagique de notebook Jupyter qui ne nécessite aucune configuration. C’est un outil populaire parmi les chercheurs et les professionnels du machine learning pour l’expérimentation, la formation des modèles et le partage des résultats. « On importe un fichier notebook Jupyter dans lequel on peut programmer en langage Python, » explique M. Pulizzotto.
La variable en Python
En Python, une variable est un conteneur pour stocker des données, et cela peu importe le type. Ici neuf types sont définis. Il est à noter que les abréviations, entre parenthèses et soulignées en gras, sont essentielles dans le code Python, et que le langage de programmation est essentiellement en anglais :
- Un entier (int) : un nombre sans décimal. int est l’abréviation de integer.
- Un nombre avec une décimale. (float)
- Une chaîne de caractères (str) : souvent appelée simplement « chaîne » (string), est une séquence qui peut être totalement vide ou de plusieurs caractères. Un caractère peut être une lettre, un chiffre, un symbole, un espace, une tabulation, un retour à la ligne, etc. En gros, n’importe quel symbole que vous pouvez taper sur un clavier.
- Des valeurs booléennes (bool) : ces valeurs sont souvent utilisées pour représenter les deux états d’une condition : vrai ou faux. Elles sont un sous-type de ‘int’. Il a seulement deux valeurs possibles : ‘True’ et ‘False’.
- Une liste (list) : ce sont des collections ordonnées d’éléments.
- Un dictionnaire (dict) : c’est un type de données utilisé pour les collections d’objets structurées comme un dictionnaire. Chaque objet est stocké et récupéré à l’aide d’une clé unique.
- Un tuple (tuple) : c’est une collection d’éléments énuméré et séparés par des virgules. Son contenu ne peut pas être changé une fois qu’il a été créé. Ex. : tuple = 1, 2, 3, 4, 5
- Un set (set) : c’est le type de données utilisé pour les ensembles qui sont des collections non ordonnées d’éléments uniques.
- Un objet (user-defined type) : c’est un type de données personnalisé que vous créez. Vous définissez vos propres règles sur la manière dont les types de données doivent être organisés et interagir, créant ainsi un nouveau type de données avec sa propre structure et ses propres comportements.
Donc une variable peut contenir des ‘int’ – ‘float’ – ‘str’ – ‘bool’ – ‘list’ – ‘dict’ – ‘tuple’ – ‘set’ – ‘user-defined type’ – etc.
Le typage dynamique
Python est un langage à typage dynamique. En d’autres termes, Python identifie automatiquement le type de donnée que vous attribuez à une variable (‘int’ – ‘float’ – ‘str’ – etc.) au moment de l’exécution du code, pas avant. Cela offre de la flexibilité en programmation car il n’est pas nécessaire de préciser à l’avance le type de chaque variable. C’est différent du typage statique, utilisé dans d’autres langages comme Java ou C++, où le type de chaque variable doit être spécifié lors de l’écriture du code.
La fonction en Python
Davide Pulizzotto explique que la fonction est une ‘str’ de caractères. C’est un ensemble d’instructions regroupées qui effectue une tâche spécifique. Elle peut prendre des données en entrée, les traiter d’une certaine manière, et renvoyer un résultat.
Les fonctions en Python, comme dans la plupart des langages de programmation, sont un outil important pour organiser et réutiliser du code :
- Réutilisation du code : si vous avez une tâche que vous devez effectuer à plusieurs endroits dans votre code, vous pouvez écrire une fonction – ‘str’ – pour effectuer cette tâche une fois, puis appeler cette fonction chaque fois que vous avez besoin de réaliser la tâche. Cela évite d’avoir à écrire le même code à plusieurs reprises.
- Organisation du code : les fonctions vous permettent de découper votre code en parties plus petites et plus gérables. Chaque fonction a un objectif spécifique. Cela rend votre code plus lisible et plus facile à comprendre, car vous pouvez voir rapidement ce que fait chaque partie du code.
- Facilité de maintenance : si vous devez modifier la façon dont une tâche particulière est effectuée, vous n’avez qu’à modifier le code de la fonction qui effectue cette tâche. Cela peut être beaucoup plus facile que de trouver et de modifier chaque endroit dans votre code où cette tâche est effectuée.
La fonction a besoin d’arguments
Dans le langage courant, un argument réfère à un raisonnement dans une discussion. Cependant, dans le contexte de la programmation, ce terme a une signification différente.
En programmation, un argument est une valeur attribuée à une fonction. Il sert à fournir des informations à la fonction pour qu’elle puisse accomplir son travail.
Donc, une fonction a besoin d’arguments (ou valeurs) pour effectuer des opérations ou des traitements spécifiques. Ces arguments servent de données d’entrée pour la fonction. Par exemple, si vous avez une fonction qui additionne deux nombres, vous devez fournir ces deux nombres en tant qu’arguments lorsque vous appelez la fonction. Ainsi, la fonction utilise ces arguments pour effectuer son travail, dans ce cas, effectuer l’addition, et retourne le résultat.
La préparation des données textuelles
a. Tokenisation
C’est un processus fondamental en traitement du langage naturel (NLP). Il s’agit de la division d’un texte en unités plus petites, appelées tokens. La traduction française est : jeton.
En général, les tokens sont des mots, mais ils peuvent aussi être des n-grammes de mots, c’est-à-dire des groupes de mots, ou d’autres unités selon le niveau de granularité nécessaire à l’analyse. Un 1-gramme signifie qu’il y a un mot par groupe. Un 2-gramme, qu’il y a deux mots par groupe, et ainsi de suite. Par exemple, dans la phrase “J’aime la programmation et le son des clics de mon clavier”, une tokenisation en 2-grammes donnerait ‘J’aime’, ‘la programmation’, ‘et le’, ‘son des’, ‘clics de’, ‘mon clavier’.
La tokenisation facilite l’analyse du texte en transformant le texte brut, qui est une chaîne de caractères continue, en une liste d’unités discrètes, plus faciles à manipuler pour les algorithmes de NLP.
b. Analyse morphosyntaxique
L’analyse morphosyntaxique, en anglais Part-of-Speech tagging (POS tagging), est une tâche du traitement automatique du langage naturel (TALN) qui consiste à attribuer à chaque mot d’un texte sa catégorie grammaticale, telle que nom, verbe, adjectif, adverbe, préposition, conjonction, etc.
c. Retirer la ponctuation
L’opération de retirer la ponctuation d’un texte dans le cadre du TALN est souvent désignée par l’expression punctuation removal. Cette étape permet d’éliminer les éléments qui ne contribuent pas à la signification du texte et qui pourraient interférer avec l’analyse ultérieure.
d. Convertir chaque caractère en minuscule
Le traitement de convertir chaque caractère en minuscule : case normalization ou lowercasing garantit que les mots sont traités de manière uniforme, indépendamment de leur place dans une phrase.
e. Retirer les mots vides
Les mots vides, ou stopwords, sont des mots qui sont généralement filtrés lors du traitement du texte car ils n’apportent pas d’informations significatives pour comprendre le sens général du texte. Ce sont souvent des mots très courants dans une langue, comme les déterminants, les prépositions, les pronoms et les conjonctions.
En Python, la bibliothèque Natural Language Toolkit (NLTK) fournit une liste de stopwords en plusieurs langues que vous pouvez utiliser pour filtrer ces mots de votre texte.
f. Ramener les mots à leur racine
Dans le domaine du TALN, on utilise deux méthodes principales pour simplifier les mots à leur forme de base : la lemmatisation et la racinisation (stemming).
La lemmatisation ramène le mot à son lemme, c’est-à-dire sa forme de base dans le dictionnaire, souvent l’infinitif pour les verbes.
Le stemming – selon la technique de Porter – va tenter de couper les affixes pour revenir à la racine du mot, qui peut ne pas être un mot existant dans le dictionnaire. Le stemming selon la technique de Lancaster (Paice/Husk stemming algorithm) utilise une table de règles, avec une règle par ligne. Chaque règle remplace un suffixe d’un mot par un autre suffixe ou le supprime.
En règle générale, le stemming, qu’il soit effectué par l’algorithme de Porter ou de Lancaster, peut parfois produire des mots qui ne sont pas de véritables mots dans la langue source. Cela est dû au fait que le stemming consiste à enlever les suffixes (et parfois les préfixes) des mots, sans tenir compte du contexte ou du sens.
Cependant, le stemming de Porter est généralement considéré comme étant plus doux et plus conservateur que celui de Lancaster. Il a donc moins de chances de produire des mots non-sens. Si la préservation du sens est plus importante, la lemmatisation ou le stemming de Porter peuvent être de meilleurs choix. Si la réduction de la taille du vocabulaire est plus importante, le stemming de Lancaster pourrait être préféré.
g. Filtrage selon le rôle morphosyntaxique
Il consiste à sélectionner ou à éliminer certains mots d’un texte en fonction de leur rôle grammatical. On peut choisir de ne garder que les noms, ou d’éliminer les adverbes, selon l’objectif de l’analyse. Le terme anglais est Filtering based on Part-of-Speech (POS).
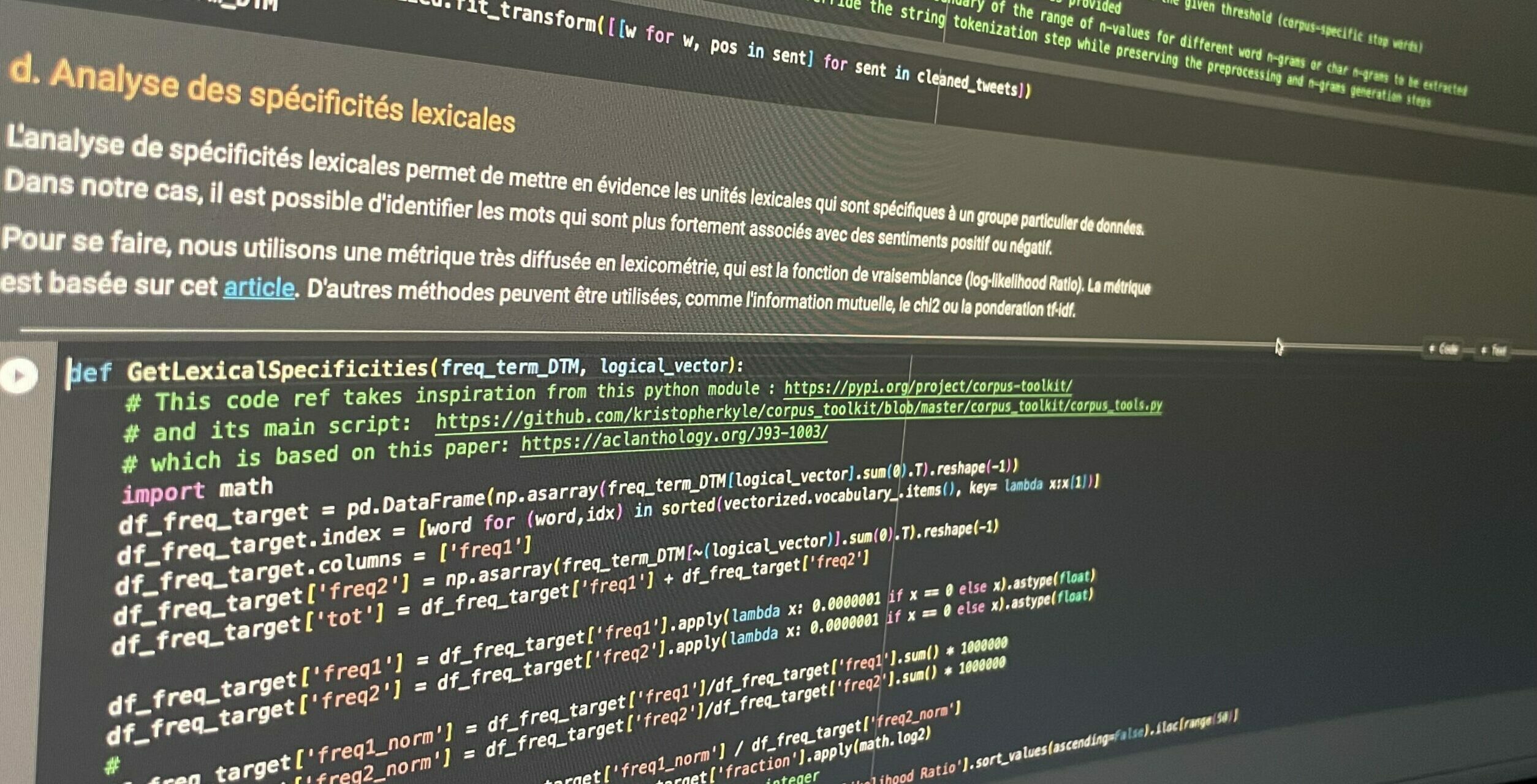
Représentation numérique du texte
Dans le traitement du langage naturel (TALN – NLP), faire un vecteur (ou la vectorisation) est une méthode pour convertir des données textuelles en une représentation numérique utilisable par des algorithmes d’apprentissage automatique. C’est un élément essentiel pour permettre aux machines de comprendre et de manipuler des données textuelles.
Ce contenu a été mis à jour le 2023-07-14 à 22 h 39 min.