La conciliation entre la cybersécurité et le besoin d’analyse des données

par Nicolas Sacchetti
Frédéric Cuppens est professeur titulaire en cybersécurité à Polytechnique Montréal. Le 8 décembre 2022, il présentait un exposé intitulé « Protection des données, peut-on gagner la partie ? » dans le cadre de la série de webinaires sur les mégadonnées et techniques avancées démystifiées de 4POINT0. Un compte rendu.
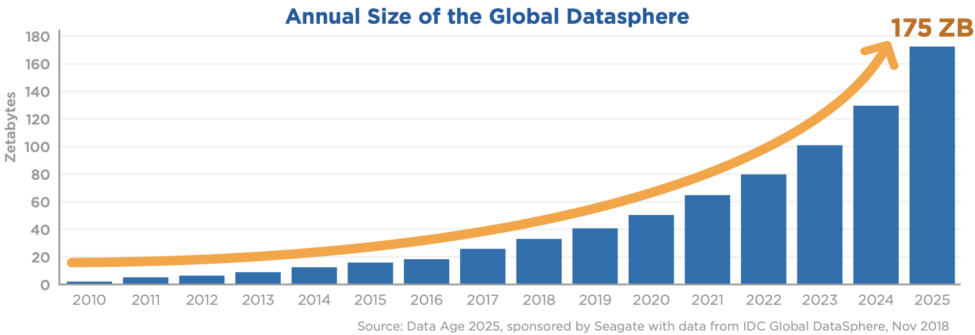
D’entrée de jeu, le professeur Cuppens rapporte les prévisions de l’International Data Corporation (IDC) qui dans son livre blanc (White Paper) de novembre 2018 prévoit que la Datasphère mondiale attendra 175 ZB (zettaoctets) d’ici 2025. Il est question ici de l’ensemble des données créées, capturées, copiées, et consommées dans le monde. Pour donner un ordre de grandeur, un zettabyte est l’équivalent d’un milliard de téraoctets (TB), et 1 TB c’est la possibilité moyenne de stockage d’un disque dur externe.
Dans un univers numérique en constante expansion, selon l’IDC, d’ici 2025 chaque personne en ligne aura une interaction impliquant des données plus de 4 900 fois par jour, soit environ toutes les 18 secondes. Avec l’Internet des objets (IoT), le même rapport de l’IDC prévoit 150 milliards d’objets connectés à l’échelle mondiale, dont la plupart produiront des données en temps réel.
Avec toutes ces données, il est évident qu’un enjeu de sécurité est présent. Pourtant, dans leur précédente publication, l’IDC précisait que d’ici 2025, presque 90% de toutes les données créées dans la datasphère mondiale nécessiteraient un niveau de sécurité, mais moins de la moitié le seront.
Face à de tels enjeux et défis, des institutions spécialisées se mobilisent pour garantir un environnement numérique plus sécurisé. C’est le cas de l’IMC2, dirigé par Frédéric Cuppens. L’Institut multidisciplinaire en cybersécurité et cyberrésilience joue un rôle crucial en venant prêter main forte pour l’avancement d’un univers numérique sécuritaire, à une époque qui, par moments, rappelle le farwest.
Sécurité et protection des données
En ce qui concerne les enjeux de sécurité et de protection des données, le professeur Cuppens établit des priorités différentes en fonction du point de vue adopté, qu’il s’agisse de l’utilisateur, de l’entreprise ou de la société dans son ensemble.

Usagers
Pour les usagers, les enjeux prioritaires concernent l’identité (nom, adresse, numéro d’assurance sociale, données biométriques, etc.), la vie privée (c’est-à-dire le contrôle que l’on a sur l’accès et l’utilisation de nos informations personnelles), et le consentement. Ce dernier est intrinsèquement lié aux deux premiers, car lorsque l’on vous demande votre autorisation pour accéder à vos informations, cette autorisation est nécessaire.
Entreprises
Les entreprises ont pour priorité la protection de la propriété intellectuelle (brevets, marques de commerce, droits d’auteur, secrets d’affaires, etc.), la préservation de leur image de marque (étant donné que des données compromises peuvent éroder la confiance des clients), et la prévention du sabotage (par exemple, les attaques malveillantes sur les systèmes informatiques).
Société
Pour la société dans son ensemble, la désinformation (informations fausses ou trompeuses), la manipulation (par exemple, le micro-ciblage ou le profilage psychographique), et le deepfake (faux contenus hyper-réalistes) posent d’importants défis, en particulier pour la confiance du public, la démocratie, la vie privée et la sécurité.
« Il est important de noter qu’aujourd’hui, en ce qui concerne l’utilisation et la production des données, il n’y a pas vraiment de séparation entre les données d’entreprises et celles à caractère personnel. Je dirais qu’il y a une forte intrication entre les deux. »
— Frédéric Cuppens, professeur titulaire en cybersécurité à Polytechnique Montréal
En effet, dans le monde numérique actuel, les données personnelles et d’entreprises sont difficilement séparables. Cette proximité est due non seulement à leur stockage et traitement souvent commun dans des infrastructures telles que l’infonuagique (cloud computing), mais surtout à leur utilisation et gestion qui sont interdépendantes.
Les entreprises ont recours aux données personnelles dans leurs activités quotidiennes. Par exemple, elles collectent des informations sur leurs clients pour mieux comprendre leurs préférences et comportements, développer de nouveaux produits, personnaliser leur publicité et leur marketing, ou encore améliorer leur service à la clientèle. Ces données peuvent inclure des noms, des adresses électroniques, des historiques d’achat, des informations de géolocalisation et des données de navigation sur le web.
D’autre part, les individus génèrent également des données qui ont une importance significative pour les entreprises. Par exemple, les employés créent des données professionnelles, comme des courriels, des documents, des projets, qui sont stockées et gérées par l’entreprise. De plus, les utilisateurs de services en ligne génèrent constamment des données d’interaction et de comportement qui sont précieuses pour les entreprises.
La datasphère mondiale : des enjeux de protection différents
Le professeur Cuppens souligne que l’évolution des entreprises a commencé par une situation où, dans le passé, les données étaient principalement utilisées par les systèmes d’information (TI – technologies de l’information). Cette tendance a ensuite évolué vers l’utilisation des données par les systèmes industriels (TO – technologies opérationnelles) dans le contexte de l’Internet des objets (IoT).
Cette évolution a entraîné un changement dans les priorités de protection des données. Dans le domaine des TI, la priorité est accordée à la confidentialité, suivie de l’intégrité, puis de la disponibilité des données. Par contre, avec l’évolution des objets connectés, les TO priorisent exactement l’inverse : la disponibilité des données est primordiale, suivie de leur intégrité, et enfin de leur confidentialité. Par conséquent, l’usage des données effectué par les systèmes industriels est très largement non protégé.
Il qualifie la situation de préoccupante due à la forte convergence entre les TI et les TO. Cela peut conduire à des situations où les données ne sont pas suffisamment protégées lorsque les systèmes TI et TO sont interconnectés. Par exemple, une donnée hautement confidentielle provenant d’un système TI peut ne pas recevoir le même niveau de protection si elle est traitée ou stockée dans un système TO.
De plus, si un système TO qui priorise la disponibilité est compromis, cela peut affecter les systèmes TI liés, et vice versa. Cette interdépendance et ce manque de cohérence dans les priorités de sécurité peuvent rendre le système global plus vulnérable aux cyberattaques et autres problèmes de sécurité.
Deux solutions parmi les possibles
1- La cryptographie
Le professeur Cuppens souligne l’importance de la cryptographie pour protéger les informations. En effet, des données chiffrées* sont des informations rendues inintelligibles à l’aide de codes et de chiffres. Ces informations ne peuvent être comprises que par les personnes disposant de la clé de déchiffrement appropriée.
*à ne pas confondre avec l’expression « données cryptées », qui pourrait suggérer une transformation unidirectionnelle d’où le texte d’origine ne peut être récupéré
« La cryptographie c’est très intéressant à la fois pour l’intégrité et pour la confidentialité des données, » explique-t-il. Ce sont deux concepts distincts en matière de sécurité informatique.
Intégrité des données
C’est l’exactitude et la cohérence des données. Les techniques visant à assurer l’intégrité des données veillent à ce qu’elles ne soient pas modifiées sans autorisation. On parle ici notamment de :
- Hachage cryptographique qui transforme une quantité variable de données en une chaîne de caractères fixe et unique ;
- Somme de contrôle, qui calcule une valeur numérique unique à partir de l’ensemble des données (si les données changent, la somme de contrôle change aussi) ;
- Signature électronique, qui offre une double garantie : elle confirme que les données n’ont pas été modifiées après avoir été signées et authentifie l’identité du signataire, assurant ainsi la non-répudiation, c’est-à-dire l’impossibilité pour le signataire de nier son implication.
Confidentialité des données
Le chiffrement renforce la confidentialité des données, mais pose en même temps un problème sur le plan de l’utilité, explique le professeur à Polytechnique Montréal. Une fois qu’on a chiffré des données, aucune information n’est accessible sans la clé. Frédéric Cuppens mentionne des solutions sur lesquelles la recherche se penche pour contourner cette contrainte d’accès. Il est question de deux grandes approches :
- Le chiffrement recherchable (searchable encryption), qui permet de retrouver des mots clés dans des données sans avoir à les déchiffrer ;
- Le chiffrement homomorphe (homomorphic encryption), qui permet de faire des opérations mathématiques sur les données, sans avoir à les déchiffrer.
2- L’anonymisation
Contrairement à la cryptographie, l’anonymisation est orientée à savoir comment partager les données de façon sécurisées. Il présente ses deux objectifs principaux :
- Rendre impossible la ré-identification (un enjeu qui touche la vie privée)
- Rendre impossible l’inférence d’information sensible (c’est-à-dire la capacité de déduire des informations sensibles à partir d’autres informations)
En ce qui concerne l’anonymisation, le professeur Cuppens mentionne qu’il y a un compromis à faire entre la sécurité et la préservation de l’utilisation que l’on veut faire des données.
Anonymisation : principales techniques et limites
Généralisation
C’est une technique d’anonymisation qui consiste à remplacer (ou généraliser) les informations précises dans un ensemble de données par des informations plus larges. Par exemple, remplacer les dates de naissance par les âges. Comme limite, il mentionne une perte importante d’utilité dans le cas d’une trop grande généralisation.
Randomisation
La randomisation est une technique d’anonymisation qui consiste à insérer de l’aléatoire dans les données pour masquer certaines informations. Parmi les différentes méthodes de randomisation, on retrouve notamment le bruitage, qui consiste à ajouter des données aléatoires (le bruit) aux données réelles, rendant ainsi difficile l’identification des valeurs véritables. Cependant, cette technique peut potentiellement affecter l’intégrité des données.
Suppression
Cette méthode implique l’élimination d’informations spécifiques, comme des détails sensibles ou privés, d’un ensemble de données. Le professeur Cuppens souligne une problématique qu’entraîne la suppression de données dans un cadre d’un objectif d’anonymisation des données.
Les données rares ou inhabituelles peuvent être plus facilement identifiables, car elles se distinguent du reste de l’ensemble de données. Par conséquent, en supprimant ces données pour les anonymiser, on risque également de perdre des informations potentiellement importantes pour l’analyse.
En contexte de recherche, ce sont souvent les cas rares, les anomalies ou les exceptions qui peuvent fournir les informations les plus précieuses ou intéressantes. Cependant, dans le cadre de l’anonymisation, la suppression de ces cas rares peut justement poser un problème. Il s’agit donc de trouver un équilibre entre la protection de la confidentialité et la préservation de la valeur des données.
« Ce qui est important de bien comprendre c’est que l’anonymisation est différente de ce qu’on appelle habituellement la pseudonymisation. Qui consiste à remplacer nos identifiants par des pseudonymes : notre nom, notre prénom, notre numéro d’assurance sociale, etc. On va pouvoir les pseudonymiser, mais malheureusement ce n’est pas suffisant. »
— Frédéric Cuppens, professeur titulaire en cybersécurité à Polytechnique Montréal
La pseudonymisation n’est pas suffisante
Pour illustrer son propos, le professeur Frédéric Cuppens présente l’histoire du sénateur américain William Weld qui dans les années 1990 aux États-Unis et a été un événement déterminant pour la compréhension de la protection de la vie privée dans l’ère numérique.
Alors qu’il était le gouverneur du Massachusetts, les données de santé de l’état ont été prétendument anonymisées, en remplaçant les noms et autres informations d’identification personnelle par des pseudonymes, puis rendues publiques pour des travaux de recherche. On pensait alors que ces données étaient suffisamment anonymes pour protéger la vie privée des individus.
Cependant, une étudiante du MIT du nom de Latanya Sweeney a démontré que cette pseudonymisation n’était pas suffisante. Sweeney a réussi à relier ces données de santé supposément anonymisées au gouverneur Weld, en utilisant simplement d’autres ensembles de données publiques, notamment les listes électorales. Elle a réussi à identifier les dossiers médicaux de Weld en croisant des informations apparemment non sensibles comme son code postal, sa date de naissance et son sexe.
L’intention d’utilisation guide de choix d’anonymisation
Le dilemme entre la protection des données par rapport à l’anonymisation et la cryptographie, et la nécessité de préserver leur intégrité et leur accessibilité en tant que ressources en source ouverte, dépend de l’objectif d’utilisation de ces données. Trouver l’équilibre entre ces objectifs parfois contradictoires constitue le défi.
« La clé réside dans la notion de finalité, » explique Frédéric Cuppens. Il précise que chaque fois que nous cherchons à anonymiser des données collectées, nous devons nous interroger sur la finalité de leur utilisation.
Les différents types de données
Dans le domaine de la cybersécurité, le professeur Cuppens mentionne trois formes de données particulièrement pertinentes : les données structurées, les données non structurées et les logs.
- Les données structurées se réfèrent à des informations hautement organisées, comme celles provenant de bases de données ou de feuilles de calcul, qui peuvent être facilement analysées.
- Les données non structurées, en revanche, comprennent des informations plus complexes à analyser, telles que les courriels, les corpus de texte, les PDF, les images, etc.
- Enfin, les logs représentent des enregistrements d’événements sur un système. Ils sont essentiels pour la surveillance des systèmes et l’analyse des activités de l’utilisateur, afin de détecter les incidents de sécurité et comprendre les comportements des utilisateurs.
En traitant ces différents types de données, les professionnels·les de la cybersécurité peuvent mieux comprendre et protéger les systèmes contre les menaces.
Protection de la vie privée
Frédéric Cuppens nous invite à réfléchir : « On peut se poser la question : est-ce que c’est une question perdue d’avance que de vouloir effectivement protéger notre vie privée par rapport à la protection de nos données ? […] Dans l’état actuel des choses, au bout du compte, l’approche et le modèle font que quelque part on accepte que nos données ne soient pas anonymisées. Le modèle actuel est d’accéder gratuitement aux services, mais en fait on paie avec nos données. Quelque part, on accepte que ces données soient manipulées sans qu’elles soient préalablement anonymisées. »
Ensuite, il souligne que des alternatives aux réseaux sociaux existent, mais qu’elles ne sont pas suffisamment exploitées. « Au lieu d’avoir une collecte massive des données, on pourrait ramener ce problème à des niveaux plus locaux où l’utilisateur·rice aurait un meilleur contrôle sur ses données, notamment en matière d’anonymisation, » explique-t-il.
Pour finir, il évoque une proposition pour la gestion des services : le micropaiement. Cette solution pourrait permettre une meilleure protection des données tout en préservant les services actuellement disponibles sur le web. En payant de petites sommes pour chaque utilisation, l’utilisateur·rice pourrait éviter de payer avec ses données.
Ce contenu a été mis à jour le 2023-09-28 à 16 h 53 min.