Structure et stockage de données (modélisation et infrastructures)

par Nicolas Sacchetti
Dans le cadre de la série de Webinaires 4POINT0 Mégadonnées et techniques avancées démystifiées en sciences sociales et humaines (SSH), le professeur Trépanier présente un atelier sur la modélisation des données. Le webinaire a eu lieu le 15 septembre 2022 dans une salle de cours de l’université d’ingénierie, et en ligne.
Martin Trépanier est professeur titulaire de la Chaire en transformation du transport (CTT) au Département de mathématiques et génie industriel (MAGI) à Polytechnique Montréal. Il y enseigne le Projet intégrateur de 3e année sur la conception d’un système d’information intégré basé sur le cas réel d’une organisation, au baccalauréat de génie industriel.
Ingénieur civil, le professeur Martin Trépanier a une expertise en planification des transports urbains et dans les systèmes de transports intelligents. Ses domaines de recherche sont la modélisation et l’analyse de données provenant des systèmes de transports, tels que les cartes à puce en transport collectif, l’automobile et le vélo communautaire, les traces GPS, les enquêtes origine-destination, etc. Ce sont des données collectées par les opérateurs de transport. Lui et ses collègues chercheurs·es utilisent des outils logiciels de conception de réseaux de transport telle que Transition, une plateforme de planification de transport urbain. Il est aussi le directeur du Centre interuniversitaire de recherche sur les réseaux d’entreprise, la logistique et le transport (CIRRELT).
Données versus informations
Dans sa présentation, le professeur Trépanier explique que le terme donnée réfère à tout élément brut tel qu’un nombre, un texte, un symbole ou une image stockée sur un support informatique, papier ou autre. Il ajoute qu’une donnée a besoin d’être contextualisée pour prendre du sens, c’est pourquoi elle est transformée en information. Par exemple, 43 est une donnée, mais lorsque le chiffre est placé dans une colonne Quantité d’un fichier, il devient une information de quantité associée à un phénomène ou une entité. Il souligne l’importance d’identifier les entités avec lesquelles on travaille dans le contexte d’analyse statistique, afin de collecter des données précises et significatives sur celles-ci.
Dans le contexte de recherches en transport, il s’intéresse à l’approche orientée objet depuis plus de vingt ans. Cette méthode de modélisation de données est toujours pertinente aujourd’hui en statistique. Elle utilise des objets —des entités uniques, concrètes ou abstraites (une voiture, une opinion) — pour représenter chaque unité de données. Chaque objet contient l’ensemble des informations pertinentes sur cette unité, telles que les variables, ou caractéristiques, et leurs valeurs respectives. Cette approche permet une meilleure compréhension et manipulation des données statistiques.
Ce qui est bien aussi, c’est qu’on peut identifier des objets d’analyse sans prétendre couvrir l’entièreté d’un sujet étudié, en se concentrant sur les éléments jugés pertinents dans le cadre du projet envisagé. Il donne l’exemple d’un cas où l’on examine un système de transport en commun avec des données précises sur les bus. Ici, il ne faut pas ignorer que d’autres modes de transport existent même si les données n’ont pas été récoltées.
Il parle d’élaboration de questionnaire avec l’idée de ce qu’on veut récolter comme données. En effet, selon David de Vaus dans son livre intitulé Research Design in Social Research, en recherche quantitative, l’élaboration d’un questionnaire fait partie d’une approche de recherche dite top-down qui implique une formulation claire de l’hypothèse de recherche et des questions de recherche spécifiques. Le questionnaire est conçu pour recueillir des données quantitatives permettant de tester l’hypothèse et de répondre aux questions de recherche. Ainsi, lors de l’élaboration d’un questionnaire en recherche quantitative, il est essentiel d’avoir une compréhension claire des variables à mesurer et des hypothèses à tester afin de concevoir des questions claires et pertinentes pour la collecte de données.
Le modèle relationnel
Le modèle relationnel (MR) est utilisé en informatique pour organiser et structurer les données. Il a été inventé dans les années 1970 par Edgar F. Codd, un informaticien britannique travaillant pour IBM. Le MR est plus simple à comprendre et à gérer, mais ces caractéristiques n’en font pas un modèle moins puissant.
Le MR représente les données sous forme de tables à deux dimensions appelées relations. Chaque relation est composée de tuples (lignes) et d’attributs (colonnes) qui peuvent être reliées entre elles par des clés primaires et des clés étrangères.
Le professeur Trépanier explique que le modèle relationnel est utilisé dans la très grande majorité des bases de données. Le taux oscille autour des 95%. Il est aussi le plus simple à comprendre. Il offre des règles très structurées pour la gestion des données, ce qui facilite le stockage et l’analyse de grandes quantités de données dans les bases de données relationnelles.
Règles de Codd
- 1. Règle de l’information
Toutes les informations dans une base de données relationnelle sont représentées de manière précise et unique.
- 2. Règle d’accès garanti
Toutes les données dans une base de données relationnelle sont accessibles par un chemin d’accès logique et direct, qui commence par un nom de table.
- 3. Règle du traitement systématique
Les opérations sur les données dans une base de données relationnelle sont effectuées systématiquement en utilisant des opérations définies.
- 4. Règle de la sous-langue
La base de données relationnelle doit supporter au moins un langage relationnel pour décrire les données, les requêtes, et les opérations.
- 5. Règle de l’intégrité
La base de données relationnelle doit supporter la définition de contraintes d’intégrité pour garantir l’exactitude et la cohérence des données.
- 6. Règle de la sous-transaction
Les transactions sont divisibles en sous-transactions qui sont soit exécutées dans leur totalité, soit annulées.
- 7. Règle du verrouillage
La base de données relationnelle doit supporter le verrouillage des données pour éviter les conflits de données.
- 8. Règle d’indépendance physique
Les applications sont indépendantes de la façon dont les données sont stockées et organisées.
- 9. Règle d’indépendance logique
Les modifications apportées à la structure de la base de données (par exemple, l’ajout ou la suppression de tables) n’affectent pas les applications existantes.
- 10. Règle de la distribution
La base de données relationnelle doit être capable d’être répartie sur plusieurs ordinateurs.
- 11. Règle de la non-sous-dépendance
Aucune dépendance transitive ne doit être autorisée entre les attributs non-clés d’une relation.
- 12. Règle de la capacité d’expression
Le langage de la base de données doit être suffisamment expressif pour permettre la définition de toutes les contraintes d’intégrité nécessaires.
Source — A Relational Model of Data for Large Shared Data Banks, Codd, 1970
Langage de requête structurée – SQL
Le langage SQL (Structured Query Language) est le langage de programmation standard pour interagir avec les bases de données qui reposent sur le modèle relationnel. Avec SQL, il est possible de créer, modifier, interroger, et gérer les données stockées dans une base de données relationnelle.
La table du modèle relationnel

Professeur Trépanier présente la table du MR. La table c’est le tableau comme tel du MR. Elle contient des enregistrements (records) sur une entité précise. L’objet de la table doit être identifié. Il fait référence au type d’entité que la table représente, comme des clients, des produits, des commandes, des employés, etc.
La table contient l’ensemble des informations que l’on souhaite stocker et gérer dans la base de données pour cet objet en particulier. Par exemple, pour une table « clients », l’objet serait les informations relatives aux clients d’une entreprise, telles que leur nom, adresse, numéro de téléphone, adresse courriel, etc.
La clé primaire du MR est un attribut ou un ensemble d’attributs qui permettent d’identifier de manière unique chaque enregistrement (ou ligne) dans une table.
Les tuples – ensemble des attributs relatif à une entité – de la table du MR contiennent des enregistrements sur une entité précise et sont composés d’attributs, tels que sur l’exemple : anneau doré, vis, planchette, pincette support mural. Ces attributs permettent de stocker et de gérer les informations relatives à l’objet de la table.
La clé primaire (primary key) est un attribut qui permet d’identifier de manière unique chaque tuple de la table. Elle est essentielle dans un contexte de création d’une base de données. Cela garantit que chaque enregistrement est unique et référence à une occurrence unique de l’entité correspondante. En plus d’empêcher les doublons d’observation et des erreurs lors d’amalgame de données, la clé primaire facilite grandement la gestion et l’intégration des données provenant de différentes sources.
Martin Trépanier ajoute qu’il est important de bien comprendre les données sous-jacentes afin de pouvoir les organiser de manière efficace dans des colonnes spécifiques. En effet, chaque colonne doit être clairement définie pour qu’elle puisse contenir les informations pertinentes et éviter toute confusion lors de l’analyse ultérieure des données.
Une compréhension approfondie des phénomènes sous-jacents permet de déterminer quelles données sont importantes à collecter et à analyser. Cela peut aider à garantir que ce qui est collecté est pertinent et utiles pour atteindre les objectifs spécifiques de l’analyse de données.
Autre composante fondamentale du MR, la clé étrangère permet de référencer la clé primaire d’une autre table en tant que colonne ou ensemble de colonnes dans une table. Donc créer des liens entre différentes tables. Cette relation, d’où le nom modèle relationnel, crée une hiérarchie et une structure logique pour la base de données, ce qui facilite l’organisation et la gestion des données. Les utilisateurs peuvent ainsi combiner les informations de plusieurs tables pour extraire des données significatives.
À titre d’exemple, dans une table de commande, la clé étrangère peut référencer le numéro de client en tant que clé primaire. La relation entre la clé primaire et la clé étrangère assure l’intégrité référentielle des données, ce qui garantit que les modifications apportées sont gérées de manière cohérente et logique.
La normalisation
Le passage de données brutes vers une base de données relationnelle requiert une transformation appelée normalisation. C’est un processus visant à organiser les données de manière optimale en réduisant les redondances et les anomalies de mise à jour, d’insertion, et de suppression. La normalisation prépare les données à être conformes aux principes qui entourent le MR.
Il y a cinq principes couramment reconnus qui entourent le MR.
- 1- L’unicité de l’identification : assurée par la clé primaire.
- 2- L’intégrité référentielle : relation entre les clés primaires et étrangères.
- 3- La normalisation : organisation optimale des données.
- 4- L’opération de jointure : combinaison d’informations provenant de différentes tables en utilisant des clés communes.
- 5- L’indépendance des données : possibilité de modifier la structure sans affecter le MR.
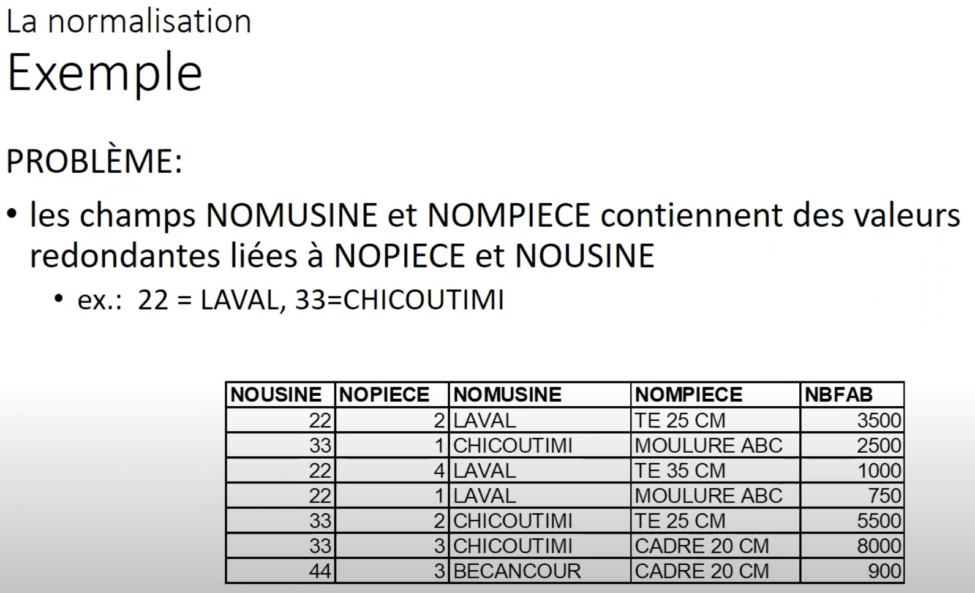
Le tableau 2 présente des données non normalisées, avec des éléments qui se répètent. Cette redondance d’information entraine une augmentation de l’espace de stockage nécessaire et réduit l’efficacité lors des opérations de recherche, mise à jour, ou suppression de données. De plus, elle peut causer des incohérences et des difficultés lors de l’intégration de données provenant de différentes sources.
Au tableau 3, on crée des tables de liaison, ou des opérations de jointure. La nouvelle table nommée PIECES_FABRIQUEES contient le lien entre le numéro – qui est la clé primaire de la table USINES, et le numéro de la pièce – qui est la clé primaire de la table PIECES.
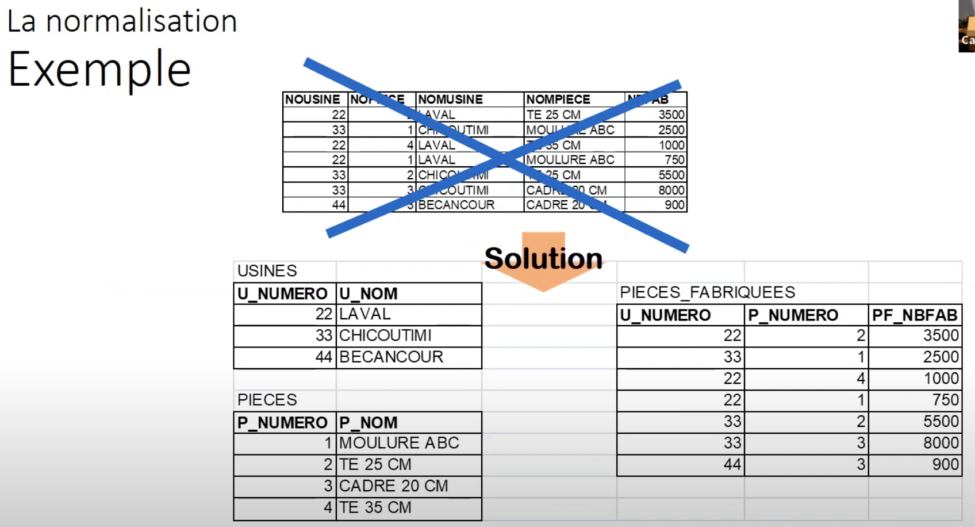
Le lien entre la pièce et l’usine est exprimé dans une nouvelle table. Elle permet la multiplicité de relations : pour la même pièce plusieurs usines qui la fabriquent, et pour la même usine plusieurs pièces fabriquées. Les bases de données Le professeur Trépanier définit la base de données comme étant un ensemble de tables géré dans un Système de gestion de base de données (SGBD) – Database Management System – DBMS). C’est un logiciel qui gère la structure, le stockage, les transactions, et la sécurité de la base de données. Quelques exemples de SGBD : Oracle, Microsoft SQL Server, IBM DB2, MySQL, PostgreSQL, Snowflake, Microsoft Access, FileMaker, MongoDB. Rôles du SGBD
- Données : Stockage, mise à jour et recherche – requêtes de données. Le langage SQL est le cœur du rôle du SGBD.
- Catalogage : La structure de la base de données est stockée dans la base de données elle-même.
- Transactions : Chaque transaction est conservée dans un journal d’activités. Les retours en arrière sont possibles.
- Multi-utilisation : Il faut vérifier que deux transactions ne modifient pas les mêmes données en même temps.
- Récupération : Les SGBD intègrent les opérations de sauvegarde (backup) des données de façon transparente.
- Sécurité : Les données ne sont pas accessibles à tous·tes les usagers·ères. Le SGBD contrôle la sécurité d’accès. Chaque usager·ère a un mot de passe.
Faire de la recherche avec des données
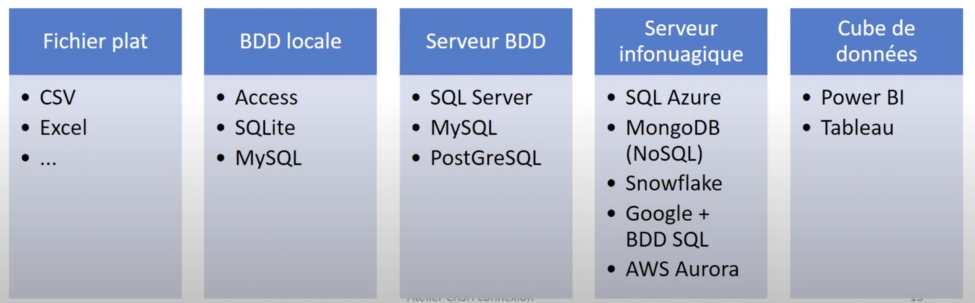
Martin Trépanier fait valoir que le support et l’infrastructure nécessaire pour faire de la recherche avec des données dépendra de la taille des données, de l’usage de ceux-ci, et du type d’analyse utilisé.
Il ajoute :
« Avec l’expérience, vu que notre recherche ne demande pas d’accès continu aux données, que les données fournies des partenaires sont souvent sous forme brute, les bons vieux fichiers plats font le travail. La puissance des outils d’analyse, comme Python et R, permet d’exploiter pleinement les données fournies sous forme brute. »
En effet, ces outils offrent une large gamme de fonctionnalités et de bibliothèques spécialisées qui facilitent la manipulation, le nettoyage, l’analyse, et la visualisation des données provenant de fichiers plats.
Il continue en disant que le montage et l’entretien des SGBD, demandent des ressources, du temps, et de l’organisation. L’utilisation des outils de haut niveau tels que Power BI ou Tableau exige une organisation des données a priori. Ce qui est souvent incompatible à la recherche. Dans ce contexte, les fichiers peuvent être fabriqués selon les besoins pour chaque chercheur·e, garantissant ainsi leur suivi et leur sécurité.
Le stockage des fichiers peut être sécurisé soit sur une plateforme infonuagique ou sur des serveurs de données locaux. Si de grandes quantités de fichiers doivent être analysées, des solutions infonuagiques comme MongoDB ou SNOWFLAKE peuvent être utilisées, mais il est également possible d’accomplir ces tâches avec un poste de travail puissant.
Ce contenu a été mis à jour le 2023-10-27 à 21 h 12 min.