L’art et la science de la visualisation des données : Une exploration avec Olivia Gélinas
par Nicolas Sacchetti
Olivia Gélinas, chargée du cours de visualisation des données à Polytechnique Montréal, définit la visualisation des données comme une représentation visuelle d’information (les données) servant des objectifs spécifiques.
Dans le cadre des webinaires 4POINT0 sur les mégadonnées et les techniques avancées démystifiées, cette formation souligne l’importance de la visualisation pour l’analyse de données et propose une ligne directrice pour perfectionner ses propres visualisations. L’événement s’est déroulé le 24 novembre 2022, en ligne et en présentiel, dans une salle de classe à Polytechnique Montréal.
La visualisation des données est un élément crucial de l’analyse des données. Elle représente le processus de transformation des données en un format graphique ou visuel, rendant ainsi les informations plus compréhensibles. Ce procédé permet de détecter des tendances, des corrélations et des modèles qui ne seraient pas immédiatement perceptibles autrement.
Selon la spécialiste, c’est un outil précieux, surtout en matière de communication d’informations, notamment lorsqu’il est question de persuasion. Elle est aussi bénéfique pour l’analyse d’informations, l’appui à des raisonnements, la validation d’hypothèses, l’identification de phénomènes ou d’erreurs, ainsi que la prise de décisions.
Les objectifs
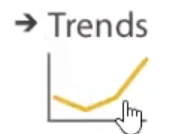
Olivia Gélinas illustre certains objectifs en visualisation de données, comme représenter une tendance ascendante à l’aide d’un graphique linéaire (fig. 1), ou mettre en évidence une donnée aberrante (fig. 2).
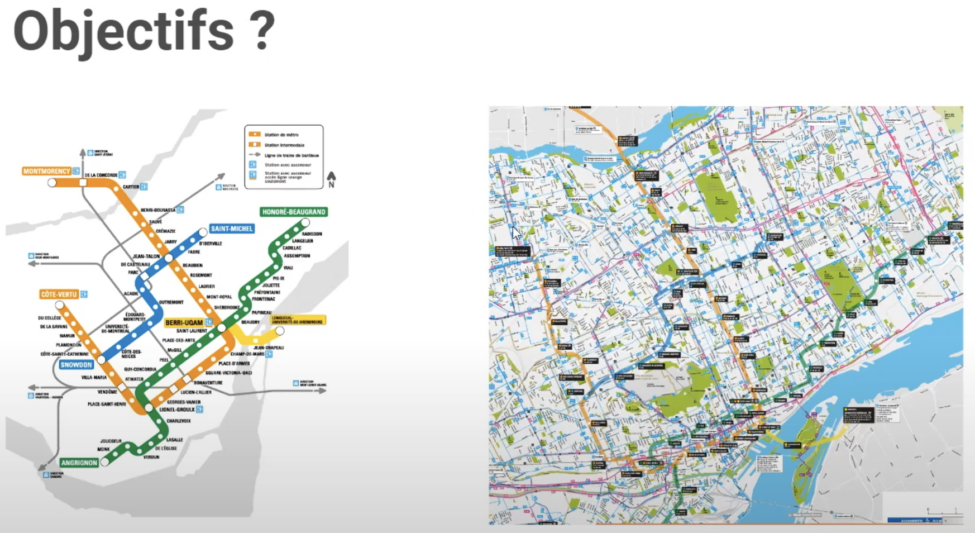
Elle illustre également cette distinction en montrant deux versions de la carte du métro de Montréal (fig. 3). Sur celle de gauche, l’objectif est de naviguer entre les stations de métro sans tenir compte de l’orientation générale dans la ville, tandis que la carte de droite met en relation les stations de métro avec leur orientation dans la ville.

Pour ceux qui souhaitent approfondir leurs connaissances en visualisation des données, elle recommande The Data Visualisation Catalogue. Elle mentionne la convivialité de la recherche par fonction. Ce projet est une bibliothèque exhaustive de différents types de représentation graphique (fig. 4), offrant une ressource d’apprentissage et d’inspiration pour ceux qui travaillent avec la visualisation de données. Chaque méthode est ajoutée après une recherche approfondie pour comprendre son fonctionnement et déterminer les cas où elle est la plus appropriée.

*implémentation : mise en oeuvre d’une idée ou du design
Processus de design
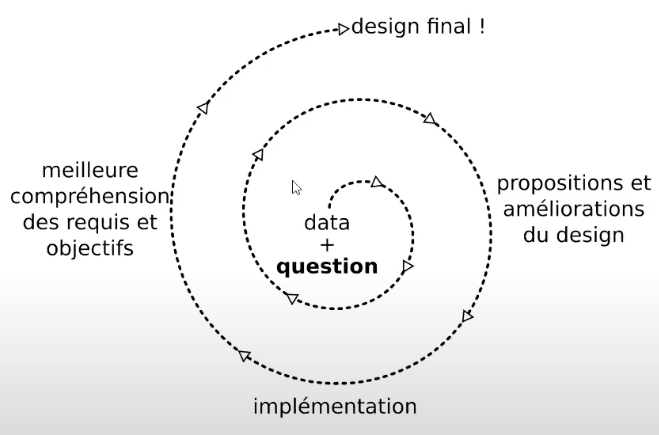
La spécialiste de la visualisation de données, Olivia Gélinas, développe sur le processus de design nécessaire à la création d’une visualisation (fig.5). Elle précise qu’il est essentiel d’identifier les utilisateurs cibles, les objectifs, les tâches, les buts et les fonctionnalités visés·es, tout en tenant compte de contraintes. Ces dernières peuvent être les données difficiles à visualiser, les différentes plateformes numériques (ordinateur, tablette, mobile, etc.) ou encore les affiches physiques sur lesquelles la visualisation sera affichée. « Cela va influencer le choix de design final, » souligne-t-elle.
L’encodage de l’information dans une visualisation de données

À la base, l’unité la plus simple est une marque. On la qualifie de primitive géométrique. Elle peut être un point, une ligne, ou une aire (fig. 6).
Pour attribuer de l’information à ces marques primitives, on utilise un canal d’encodage. Olivia Gélinas le définit comme étant la variable visuelle qui permet de lier la donnée à une marque : « Si l’on place uniquement un point sur une page, il n’y a pas d’encodage d’information. Toutefois, lorsqu’on y ajoute un axe 𝒳, un axe 𝒴, et qu’on positionne le point – on utilise le canal d’encodage qui est la position. À ce moment, il y a un encodage de deux informations. »
Outils pour caractériser les marques primitives

Types de canaux
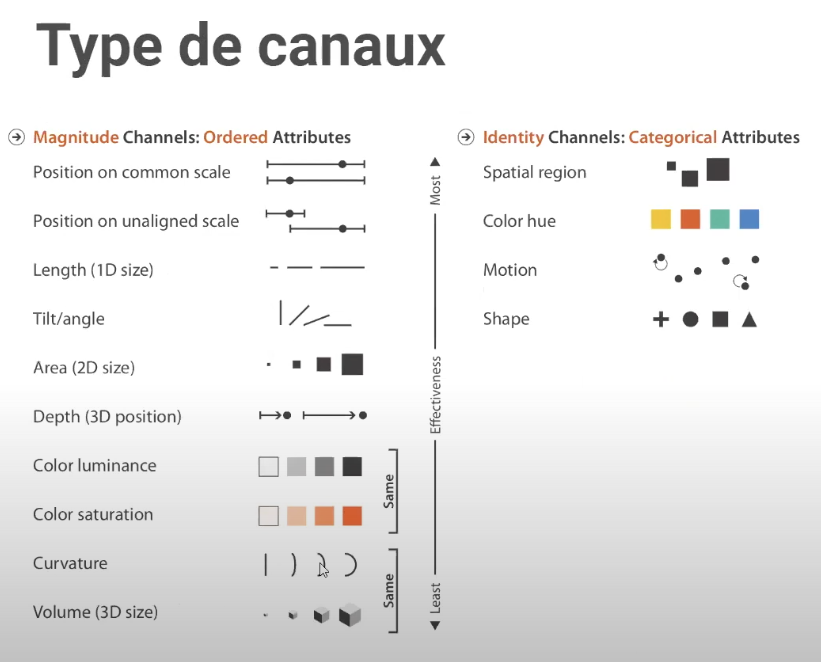
Sur l’image des types de canaux (fig.7), Olivia Gélinas met l’accent sur les deux catégories : les canaux ordonnés et les canaux catégoriques.
Les canaux d’identité (identity channels) et de magnitude (magnitude channels) sont utilisés pour représenter des variables dans un graphique ou une autre forme de visualisation.
Canaux d’identité (Identity Channels)
Ces canaux sont utilisés pour représenter des données catégorielles, où chaque valeur est distincte et n’a pas de relation ordonnée avec les autres. Elle donne comme exemple que différentes couleurs (color hue) n’ont pas d’ordre particulier.
Canaux de magnitude (Magnitude Channels)
Ces canaux sont utilisés pour représenter des données quantitatives, où les valeurs ont une relation ordonnée ou de magnitude les unes par rapport aux autres. Ici, la saturation d’une couleur peut être ordonnée.
Quelques exemples de canaux
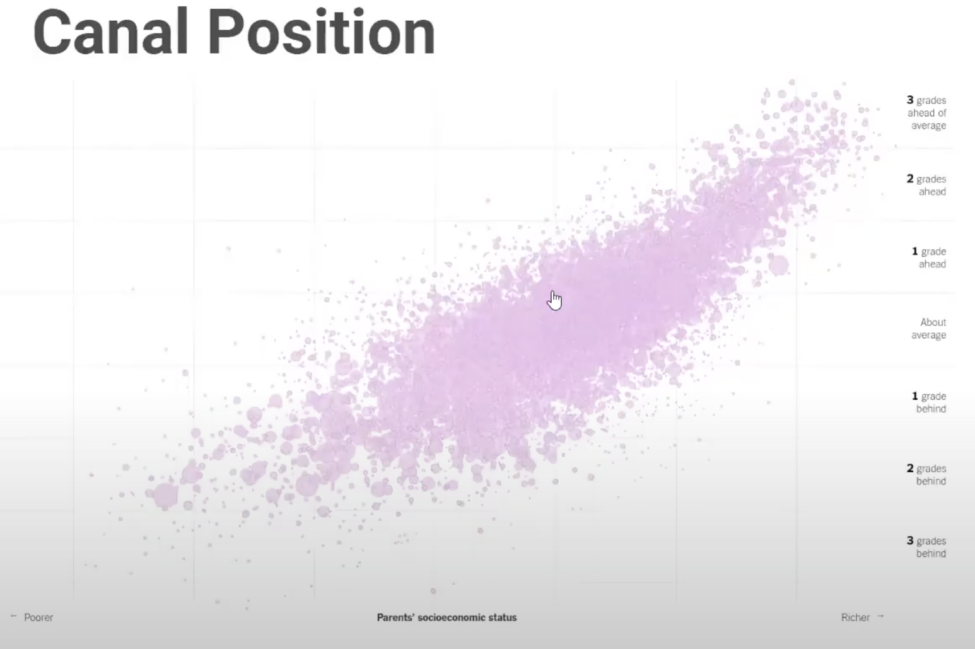
Canal position
C’est la façon dont les points de données sont positionnés spatialement sur un graphique.
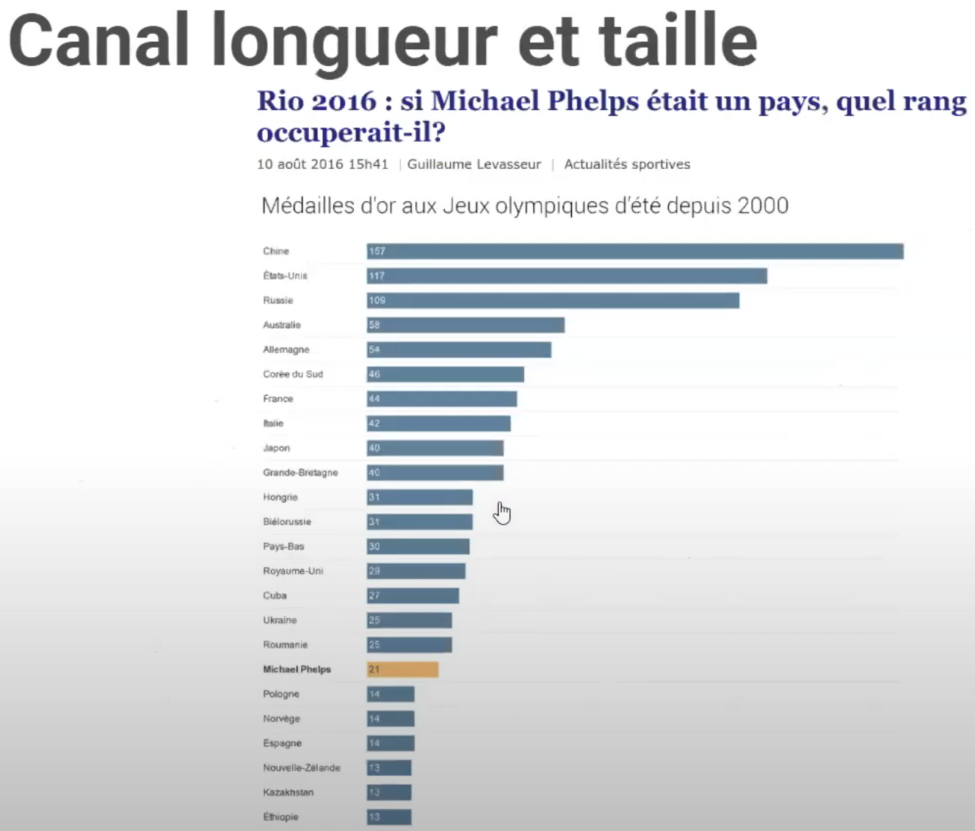
Canal longueur et taille
Utilise la longueur et la taille d’un objet, comme une barre dans un graphique à barres, pour représenter une valeur de données.
Canaux préattentifs
Ce sont des aspects visuels qui attirent l’attention instantanément et sans effort conscient lors de la visualisation de données. Ils incluent des éléments tels que la couleur, la forme, le mouvement et la taille.

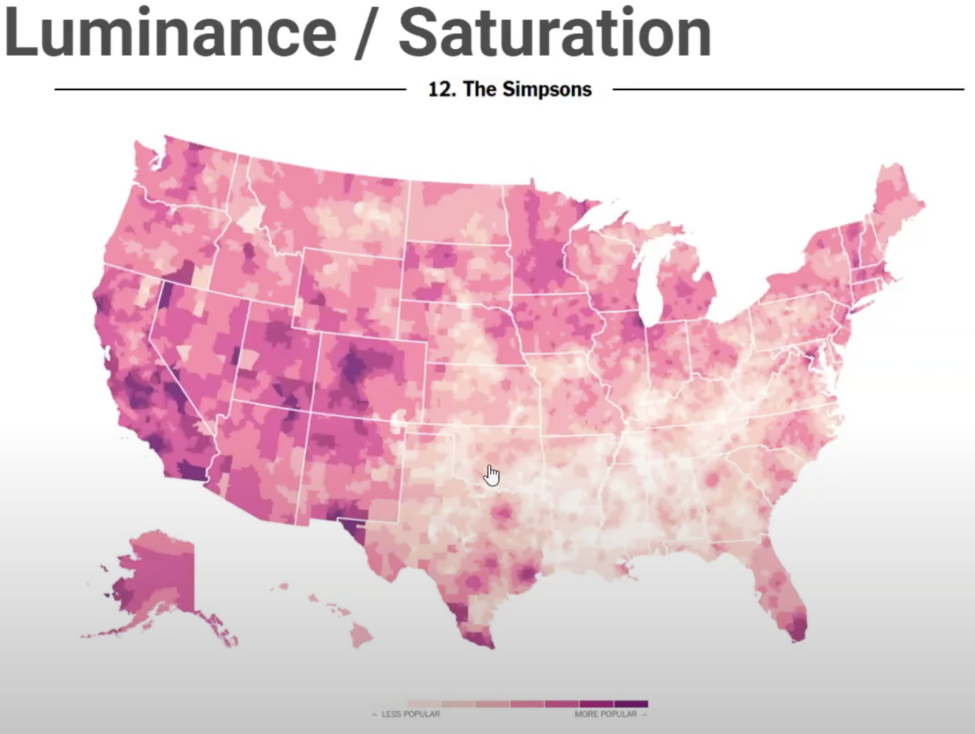
Canaux de luminance et de saturation
Ces canaux utilisent l’intensité lumineuse et la vivacité d’une couleur pour représenter des données.
Canal de couleur
Emploie différentes couleurs pour représenter et distinguer les différentes catégories de données dans une visualisation.

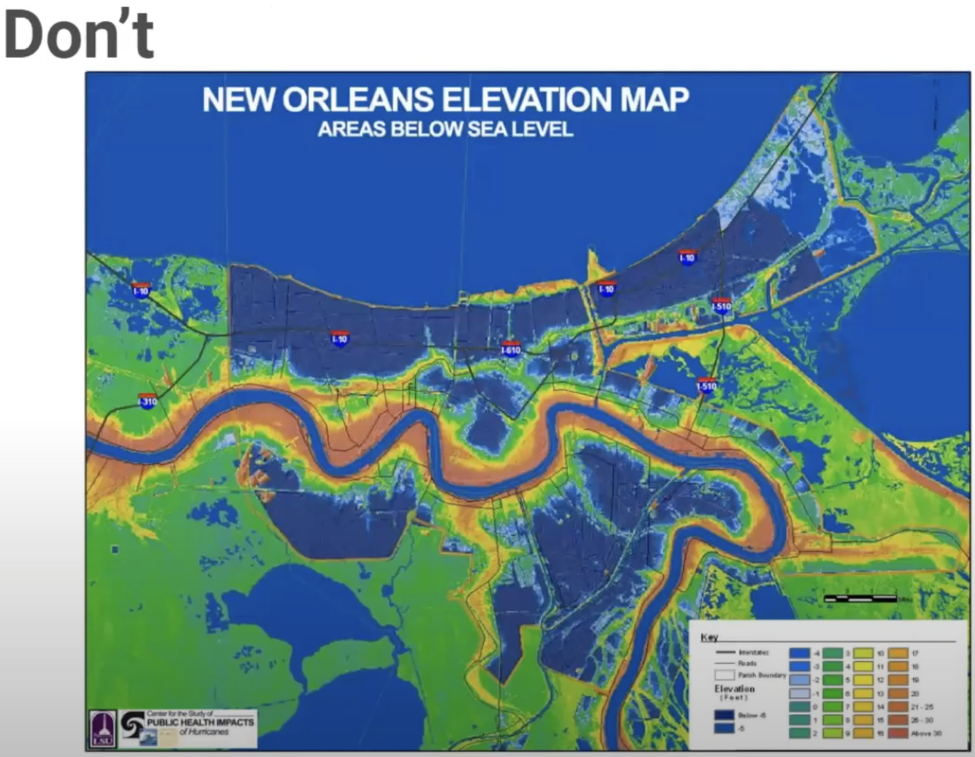
Sur la figure 8, Olivia Gélinas présente un mauvais usage des canaux ordonnés et catégoriques. Elle prend pour cas d’étude une carte de La Nouvelle-Orléans qui illustre les différentes élévations par rapport au niveau de la mer. La légende commence à -4 (en bleu) et se termine à +30 (en rouge foncé) pour les décrire. Selon Olivia Gélinas, c’est une fausse piste, car on utilise une échelle catégorique pour représenter des données ordonnées. Elle explique : « Les nombres de -4 à +30 sont ordonnés, et 4 couleurs différentes sont utilisées. Il n’y a pourtant pas quatre catégories à montrer, ni quatre réalités, peut-être deux : le négatif et le positif. Il aurait peut-être pu y avoir deux couleurs à différentes saturations. L’échelle de couleurs aurait dû être ajustée pour une meilleure compréhension intuitive du niveau d’élévation. »
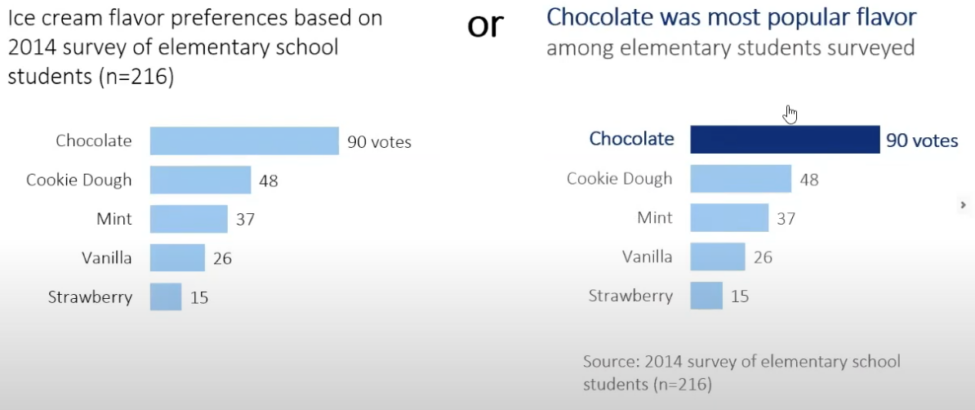
Les intentions
Olivia Gélinas conseille certains outils en complément de la représentation visuelle des données pour supporter le message. Elle explique que l’on peut rajouter titre, sous-titre, annotation, et utiliser une saturation de couleur pour faire ressortir certains points.
«Do your viewers want to see the data presented as-is, or do they want to cut to the chase and interpret the data? »
— Ann Emery
Les 10 commandements du designer
1. Tu identifieras le public et les tâches cibles, et tu t’y réfèreras à chaque itération de design.
- 1.1 Questions à se poser à chaque itération (répétition)
- 1.1.1 Quel est le but de cette visualisation ?
- 1.1.1. a) Quelle(s) question(s) cette visualisation doit-elle aider à répondre ?
- 1.1.2. Qu’est-ce qui est facilement visible dans ce design ?
- 1.1.2. a) Quelle information peut-on extraire facilement de cette visualisation ?
- 1.1.3. Quelle pourrait être une visualisation alternative ?
- 1.1.3. a) Toujours élargir, itérer (design divergent – convergent)
2. Tu itèreras et critiqueras tes designs autant que possible, parfois en repartant de zéro.
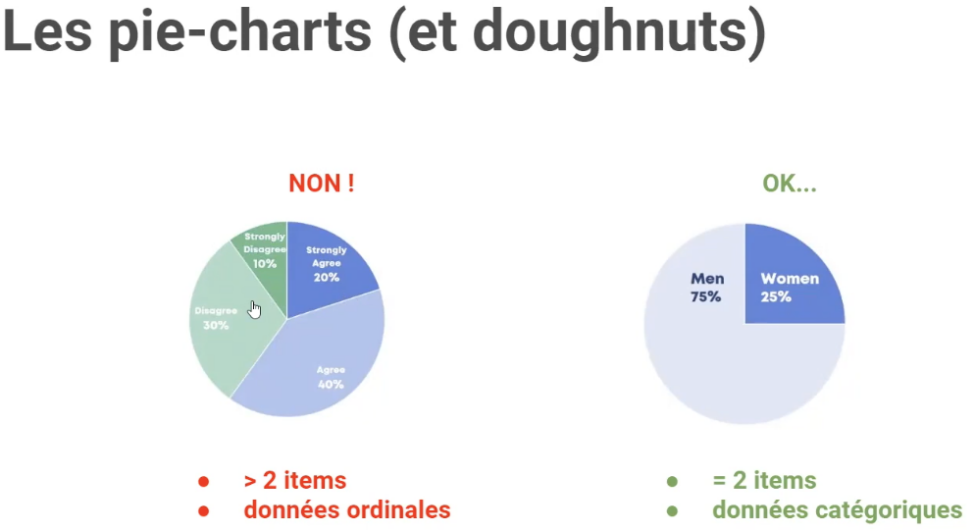
3. Tu n’utiliseras pas de canal donnant la perception d’un ordre pour des données catégorisables (et vice versa).
4. Tu ne feras pas d’échelles avec plusieurs teintes.
5. Tu réfléchiras à deux fois avant de faire une carte.
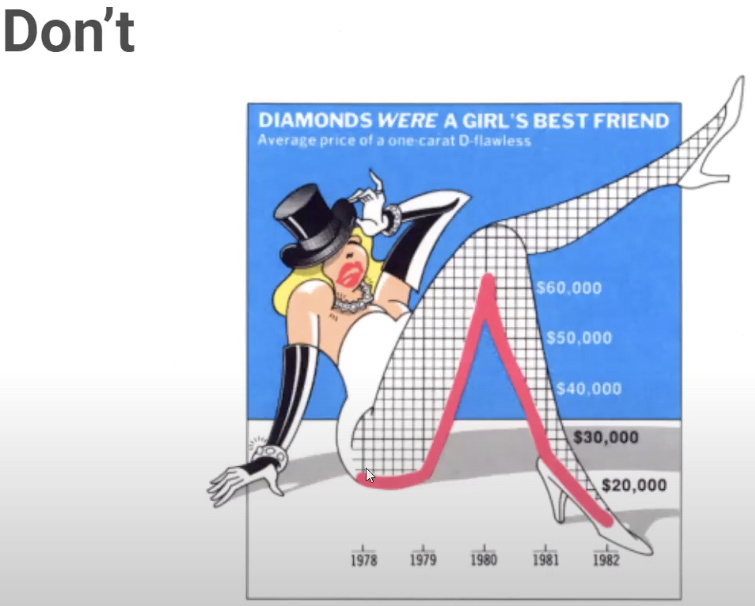
6. Tu ne biaiseras pas la perception de l’information en faisant de la visualisation de données. (encodages proportionnels, démarrer les axes à 0, etc.) (fig.9)
- 6.1 Maximiser le ratio données-encre : la surface de la visualisation consacrée aux données ÷ par la surface totale de la visualisation. (fig.10)
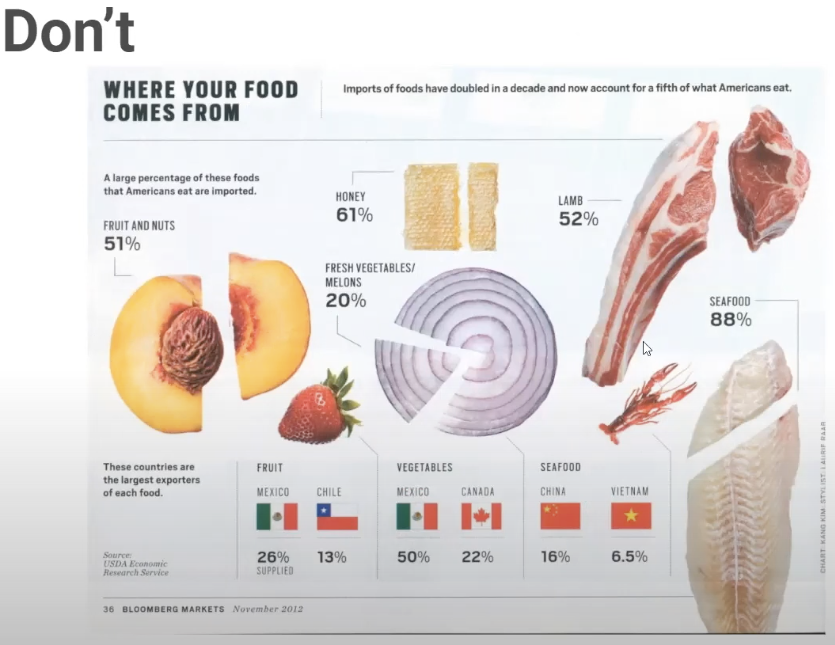
7. Tu n’utiliseras pas de graphiques inutiles (junk charts) – représentations graphiques trompeuses, qui manquent de clarté, etc. – ou de 3D.
- 7.1 Dans l’éventualité où la 3e dimension est nécessaire, utiliser un autre canal d’encodage comme la couleur ou autre.
8. Tu contextualiseras l’information sans avoir peur de montrer les données dans le détail.
9. Tu feras un diagraphe à secteur (pie chart) uniquement si tu as deux données catégoriques. (fig.11)
10. Tu faciliteras la lecture (mais avec intégrité) : mise en relief, onboarding.

Olivia Gélinas vous invite à lire cet article comme complément d’information
When Maps Shouldn’t be Maps par Matthew Ericson
Ce contenu a été mis à jour le 2023-09-22 à 19 h 00 min.